This is a follow up to an earlier post asking if persistent storage is a good idea for containers. I received good feedback on that post with readers falling on different sides of the issue. So I thought it would be worthwhile to respond by talking about three “approaches” for handling persistence for containers. I put “approaches” in quotes because I want to argue that the old adage is true here that “just because you can do it doesn’t mean you should do it.”
Let’s start by clarifying what we mean when we talk about persistent storage in this context. I’ve had some discussion with folks who wanted to know how it would be possible to run any type of application without some way to persist data. To be clear, running containers doesn’t mean the complete absence of data persistence. However, the typical persistence layers for containers have been object stores such as S3, databases consumed as a service such as RDS, and databases running in virtual machines or bare metal servers. In each use case, data is not stored in the container file system but accessed over network ports. When we talk about persistent storage in the context of these two blog posts, we are referring to mounting a volume to the container host and attaching it to the container. That volume exists outside the container and is typically used for persisting transactional data. These volume have historically been local storage on the container host but can also include networked file systems and networked block storage.
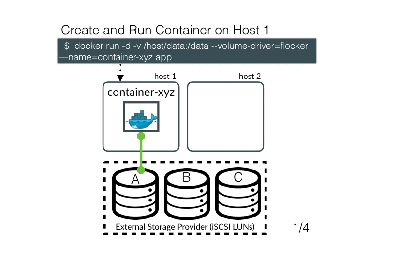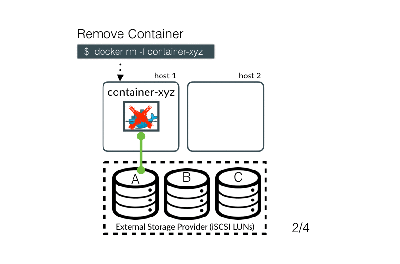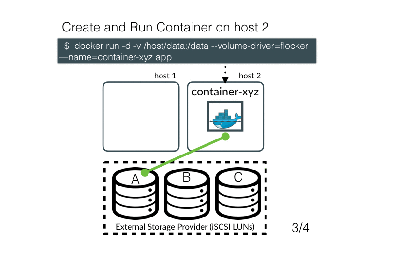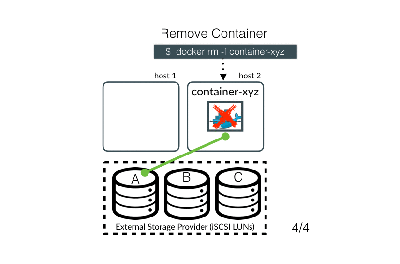
Focusing on transactional data persistence, let’s review the three approaches for providing storage for containers:
- Cloud-Native – Following pure cloud-native design patterns, such as those outlined by the Twelve-Factor App, this approach assumes that persistent data is not stored with the container but by attaching backing services, such as object stores and Databases-as-a-Service. This approach ensures that containers and their backing services which provide data persistence are loosely coupled and does not require a dependency which limits scalability. Resiliency is not provided by shared infrastructure, such as networked storage, but by the application running in containers working in concert with container management platforms.
- Containers as VMs – In an effort to take advantage of some of the benefits of containers such as application portability, some users are treating containers as light-weight virtual machines. With this approach, some are simply taking their legacy applications, such as Oracle, and migrating them from VMs to containers. This includes mounting shared network storage volumes to the containers for use as the database store. While this is an architecture that can work, it also comes with real constraints and limitations. For example, restarting a container, even with shared storage, is not the same as with restarting a kernel mode VM in vSphere. When a container is restarted on a new container host, the expectation is that the application is able to recover from the restart and reconnect tot he database volume. In contrast legacy applications make the assumption that the VM infrastructure will handle recovery without the application needing to be involved. Also, if portability is a reason for moving to containers, using them to replace VMs that are hosting legacy applications is an anti-pattern for such portability. Storing data in large volumes that are tightly coupled to the container makes portability very difficult. Limitations like these make a VM direct container approach problematic.
- Hybrid – A third approach that I call hybrid, for lack of a better term, uses volumes with containers for hosting applications with transactional persistence requirements. However, unlike the containers as VMs/ legacy app approach, this approach narrows the use case for persistent storage approach to applications that do not required shared infrastructure for resiliency or recovery. An example of this would be a non-relational database, such as Cassandra, that has availability architected at the application layer and has different expectations of the infrastructure than legacy applications. With this approach the persistence layer provide value, not by being resilient, but by being programmable and elastic, e.g. scale-out storage with good APIs. This approach combines a layer of persistence with a more or less pure cloud-native design pattern.
I’ve only been able to provide a high-level overview of the issues. I will be writing in the future to provide more details on a couple of the above approaches. Meanwhile, if you are planning to attend the OpenStack Summit in Austin and would like to hear more about this topic, I, John Griffith from SolidFire, and Shamail Tahir from IBM have submitted a talk on persistent storage with containers; please strongly consider voting for the talk during the voting period between February 9th and February 17th. And as always, feedback, corrections, and rebuttals on this post is always welcomed.
