
This is the first of a series of blog posts on the Apache Mesos project and technology. We begin first with an introductory overview.
I have a confession to make… I’ve come to loathe the term “Software Defined Data Center (SDDC).” I don’t have a problem with the concept; my issue has to do with how the term has been misused and co-opted to by companies eager to position themselves as being innovators in the next generation data center. Specifically, I would argue that being able to run your software on commodity x86 hardware does not alone constitute a SDDC solution and neither does the ability just to virtualize hardware into a pool of resources. A true SDDC, in my opinion, is one where the underlying infrastructure is abstracted away from the applications running on them so theses applications can be dynamically and automatically assigned and reassigned to run in different parts of the data center depending on the changing requirements of the application.
That’s why I’ve been very excited of late about an open-source Apache project called Mesos. Why am I so excited about Mesos? Think back to the beginning of x86 virtualization and the promise it had for making the data center more efficient by increasing server utilization and more agile by abstracting applications from the physical infrastructure. While there have been great gains, the unit of a virtual machine was not granular enough and our applications were too monolithic to fully deliver on this promise. Today, technologies such as containers and the growth of distributed applications and microservices have the potential to change the way we run and manage the applications in our data centers.

A short history of Mesos may help set some context for the rest of this and upcoming blog posts. You can trace the genesis of Mesos to a home-grown data center resource manager, created by Google, called Borg. You can read more about the origins of Borg and it’s impact on Mesos in this article by WIRED Magazine. Google’s use of Borg became the inspiration for Twitter to develop a similar resource manager that could help them get rid of the dreaded “Fail Whale.” They latched on to a project being worked on at the University of California at Berkeley AMPLab called Mesos. The UC Berkeley team working on the project was led by a PhD student named Ben Hindman who eventually went to work for Twitter and led the development and deployment of Mesos at Twitter. Today, Mesos manages the placement of workloads for over 30,0000 servers at Twitter and the Fail Whale is a thing of the past. Mesos is also deployed at companies such as Airbnb, eBay, and Netflix.
How does Mesos allow companies, like Twitter and Airbnb, scale their applications through more efficient management of their data center resources? It begins with a rather simple but elegant two-level scheduler architecture.
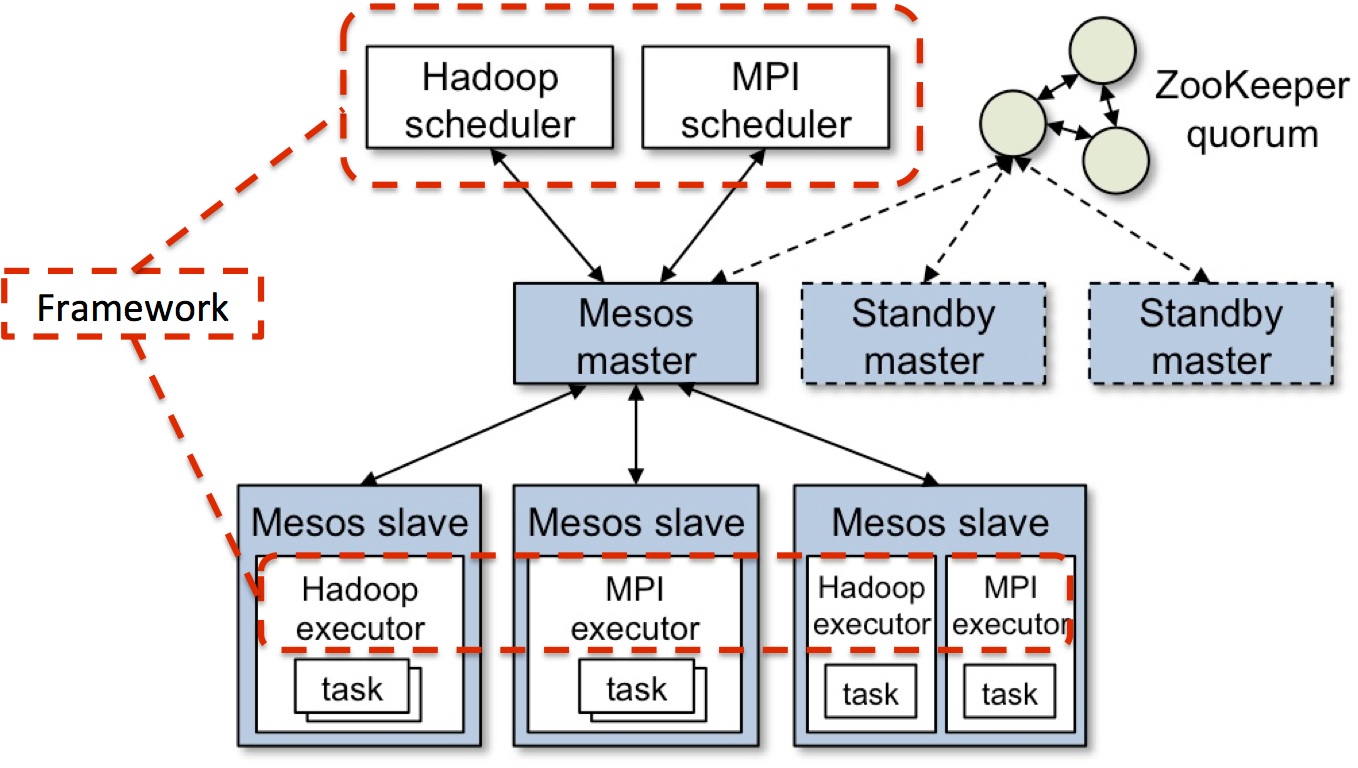
The modified diagram above from the Apache Mesos website shows how Mesos implements it’s two-level scheduling architecture for managing multiple types of applications. The first level is the master daemon which manages slave daemons running on each node in the Mesos cluster. The cluster consists of all servers, physical or virtual, that will be running applications tasks, such as Hadoop and MPI jobs. The second level consists of a component called a framework. A framework includes a scheduler and an executor process, the latter of which also runs on each node. Mesos is able to communicate with different types of frameworks with each one managing a different clustered application. The diagram above shows Hadoop and MPI but other frameworks have been written as well for other types of applications.
The Mesos master works with its slaves to determine each node’s available resources, aggregates all reported available resources across all nodes, and offers them to frameworks that have registered with the master as a client. Frameworks can choose to accept or reject resources offers from the master based on the requirements of the application using that framework. Once offers are accepted, the master coordinates with the frameworks and the slaves to schedule tasks on the participating nodes and to execute them in containers so that multiple types of tasks, such as Hadoop and Cassandra, can run simultaneously on the same nodes.
I will be diving into the details of the Mesos architecture and workflow in future blog posts. But this two-level scheduler architecture and the algorithms and isolation techniques that Mesos uses to enable resource sharing across multiple types of applications on the same nodes is, in my opinion, the future of the data center. As I wrote earlier, it is the best readily available technology I’ve seen so far to deliver on the promise of the SDDC.
I hope this introduction was helpful and has whetted people’s appetite to learn more about Mesos. In upcoming weeks, I’ll be diving deeper into the technology, giving folks some ways to get started, and talking about how to get involved in the community.
I dig deeper into the technology here, delve into persistent storage and fault tolerance in Mesos here and go under the hood of resource allocation in Mesos here. You can also read my post on what I see as going right with the Mesos project. If you are interested in spinning up and trying out Mesos, I link to some resources in another blog post.

Dear Ken, thanks for writing this article and raising the question about SDDC and Mesos. We look forward to seeing your other articles. Also liked the referenced Wired article. Thanks!
Wonderful Article. I am really fascinated by Mesos
[…] my previous post, I provided the proverbial 10,000 foot overview of Apache Mesos and it’s value as a resource […]
[…] Apache Mesos: The True OS For The Software Defined Data […]
[…] part 1 of this series on Apache Mesos, I provided a high level overview of the technology and in part 2, I […]
Hi Kenneth ,
I am the editor of InfoQ China which focuses on software development. We like your articles and plan to translate them.
Before we translate it into Chinese and publish it on our website, I want to ask for your permission first!
In exchange, we will put the English title and link at the beginning of Chinese article. If our readers want to read more about this, he/she can click back to your website.
Thanks a lot, hope to get your help. Any more question, please let me know.
Thank you. Happy to help spread the knowledge.
[…] the other posts in this series if you have not already done so. An overview of Mesos can be found here, followed by an explanation of its two-level architecture here, and then a post here on data […]
[…] Part 1: True OS For The SDDC […]
[…] Hui has a nice series running on Mesos. First, he provides a high-level overview of Mesos; that’s followed up by a slightly deeper look at Mesos, then a discussion of persistent storage […]
[…] good series on @apachemesos https://cloudarchitectmusings.com/2015/03/23/apache-mesos-the-true-os-for-the-software-defined-data-c… […]
[…] Part 1: True OS For The SDDC […]
Hi Kenneth ,
Thank you for your great blog!
You said that Mesos manages the placement of workloads for over 300000 servers at Twitter.
Where did you get the information? Do you have any other similar data about the usage of Mesos?
Best regards,
KiwenLau
Kiwen,
Thank you for the encouraging words. 🙂
I’ve heard that at various Mesos talks from folks who used to work at Twitter, though Twitter won’t validate that number. You can find other usage information on the Apache Mesos web page.
Ken
[…] APACHE MESOS: THE TRUE OS FOR THE SOFTWARE DEFINED DATA CENTER?; Mesos […]
[…] Apache Mesos – the true OS for the software defined data center […]