
In my previous post, I provided the proverbial 10,000 foot overview of Apache Mesos and it’s value as a resource manager for the data center. It’s time to dig a little deeper into the technology and walk though the components that make Mesos such a great candidate for a data center OS kernel. Most of the details I am walking though comes from a white paper that Ben Hindman and his team at UC Berkeley published back in 2010. Btw it is worth noting Hindman has moved on from Twitter to Mesosphere, a startup that is building and commercializing a data center OS with Mesos as the kernel. I will focus on distilling the main points of the white paper and then offering some thoughts on the value of the technology.
The Mesos Workflow
Le’s start by picking up where we left off in my previous post and looking at the diagram and description below from the aforementioned UC Berkeley white paper and from the Apache Mesos website:

Let’s walk through the events in the figure above. Remember from last time that the slaves are Mesos daemons running on either physical or virtual servers that are part of the Mesos cluster. A framework is a combination of an application scheduler and task executor that is registered with Mesos to take advantage of resources in the Mesos cluster.
- Slave 1 reports to the master that it has 4 CPUs and 4 GB of memory free. The master then invokes the allocation policy module, which tells it that framework 1 should be offered all available resources.
- The master sends a resource offer describing what is available on slave 1 to framework 1.
- The framework’s scheduler replies to the master with information about two tasks to run on the slave, using <2 CPUs, 1 GB RAM> for the first task, and <1 CPUs, 2 GB RAM> for the second task.
- Finally, the master sends the tasks to the slave, which allocates appropriate resources to the framework’s executor, which in turn launches the two tasks (depicted with dotted-line borders in the figure). Because 1 CPU and 1 GB of RAM are still unallocated, the allocation module may now offer them to framework 2.
Resource Allocation
To achieve the goal of allowing multiple tasks to run on the same set of slave nodes, Mesos uses what it calls isolation modules to allow a number of application and process isolation mechanisms to be used for running those tasks. It’s probably no surprise that although an isolation module could be written to use virtual machines for isolation, the current supported modules are for containers. As far back as 2009, Mesos leveraged Linux container technologies like cgroups and Solaris Zone and those are still the defaults. However, the Mesos community has added support for Docker as the isolation mechanism for running tasks. Whichever isolation module is used, the executor packages up all that is needed to run a particular application’s task and launches it on the slaves that have been assigned to that task. When a task is complete, the containers are “broken down” and the resources released for other tasks.
Let’s also dig a little deeper into the concepts of resource offers and allocation policies since they are integral to how Mesos manages resources across a number of frameworks and applications. We noted earlier the concept of resource offers made by the master to its registered frameworks. Each resource offer contains a list of free CPU, RAM, etc. resources available on each slave node. The master offers these resources to its frameworks based on allocation policies that could be universally applied across all frameworks or applied to a particular framework. A framework is free to reject resource offers which do not satisfy its requirements which then allows the resources to be offered to other frameworks. Resource starvation of any given framework is mitigated by the fact that the applications managed by Mesos typically have short-running tasks which allows resources to be quickly freed up; slaves regularly reports on its available resources so that the master can constantly make new resource offers. Additionally, techniques such as having each framework filter out unqualified resource offers and having the master rescind an offer after a given time period has elapsed can also be used.
An allocation policy helps the Mesos master determine if it should offer current available resources to a particular framework and if so, how much of those resources to offer. It would probably be worthwhile for me to write a separate post just on resource allocation in Mesos and how its pluggable allocation modules allows for very fine grain resource sharing. For now, keep in mind that Mesos implements a fair sharing and a strict priority (I’ve talk more about both in the resource allocation post) allocation module to ensure optimal resource sharing for the majority of use cases. New allocation modules can and have been written to address additional use cases.
Putting Things Together
Now to the “so what” question when it comes to Mesos. For me, I am most excited by four benefits of the technology (outlined below) and how, as I iterated in my previous post, I see Mesos as becoming the true OS kernel for the next generation data center.
- Efficiency – This is probably the most obvious benefit and one that the Mesos community and Mesosphere often touts.

The diagram above from the Mesosphere website illustrates the benefits in efficiency provided by Mesos. In most data centers today, static partitioning of servers is the norm, even with newer applications such as Hadoop. This is often the case due to concerns over different application schedulers conflicting and essentially “fighting” each other for available resources when using the same nodes. Static partitioning is inherently inefficient since you will often have periods where one partition may be resource starved while another is under-utilized and there is no easy way to reassign resources across partitioned clusters. By using a resource manager like Mesos to be the arbiter between different schedulers, you can move to a dynamic partitioning/elastic sharing model where all applications can use a common pool of nodes to safely maximize utilization. One often cited example is taking slave nodes that usually run Hadoop jobs and dynamically assigning them to run batch jobs during idle periods and vice versa. It’s worth noting that some of this can be done with virtualization technologies such as VMware’s vSphere Distributed Resource Scheduler (DRS). However, Mesos has the advantage of being more granular since it allocates resources at the application layer and not the machine layer and it assigns tasks via container instead of an entire virtual machine (VM). The former takes into account specific requirements of each application and what an application’s scheduler knows is the most efficient use of resources; the latter allows better “bin packing” since there is no need to instantiate an entire VM, just the processes and binaries required to run a task.
- Agility – Closely tied to efficiency and utilization, this is actually what I consider the most important benefit. While efficiency often addresses the “how do I save money by maximizing my data center resources,” agility addresses the “how do I move quickly using the resources I have on hand.” If we assume, as I do and as my colleague Tyler Britten often states, that IT exists to help businesses either make money or save money; then how quickly we can help generate revenue through technology is a key outcome for us to achieve. That means ensuring that key applications do not run out of needed resources because we don’t have enough infrastructure underneath them, especially when there are fee resources elsewhere in the data center.
- Scalability – One thing I really appreciate about the Mesos architecture is that it is designed to scale. This is an important attribute given the exponential growth of data and also the increased adoption of distributed applications. We are growing well beyond that point where having a monolithic scheduler or being limited to 64 node clusters are sufficient for this new breed of workloads.
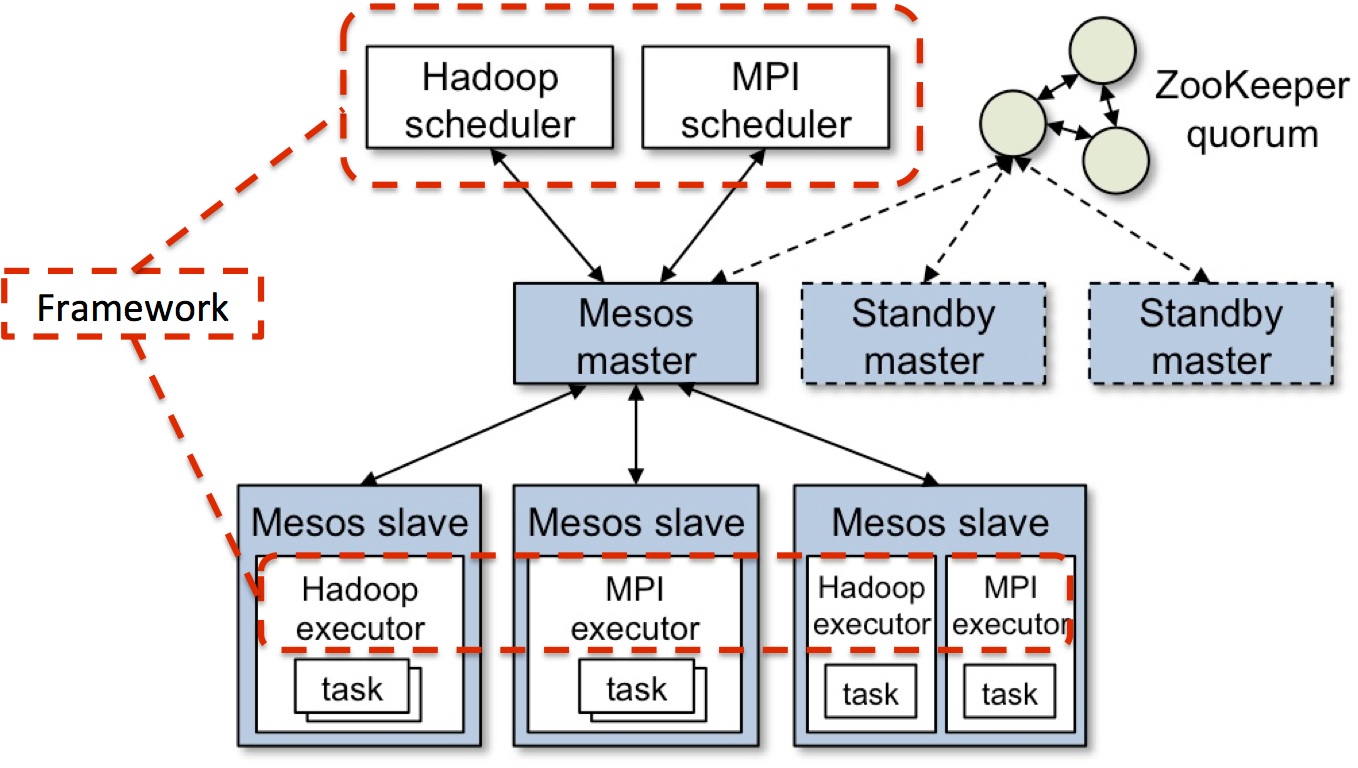
A key design point that allows Mesos to scale is its use of a two-level scheduler architecture. By delegating the actual scheduling of tasks to frameworks, the master can be a very light-weight piece of code that is easier to scale as the size of the cluster grow. This is due to the fact that the master does not have to know the scheduling intricacies of every type of application that it supports. Also, since the master does not have to do the scheduling of every task, it doesn’t become a performance bottleneck at scale as often happens when you have a monolithic scheduler that schedules every task or VM.
- Modularity – For me the future health of any open source technology can be predicted in large part to the ecosystem which surrounds that project. I think that bodes well for the Mesos project since it is designed to be inclusive and to allow plugins for things like allocation policies, isolation mechanisms, and frameworks. The benefits of allowing container technologies like Docker and Rocket to plug in is obvious. But I want to focus here on the ecosystem that is building around frameworks. By designing Mesos to delegate task scheduling to application frameworks and adopting a plugin architecture, the community has created an ecosystem that allows Mesos to become the über resource manage for the data center. It enables rapid growth in the breadth of what Mesos supports since there is no need to add in brand new code to the Mesos master and slaves modules every time a new framework is iterated. Instead, developers can focus on their application and framework of choice. The list of current but constantly growing Mesos frameworks can be found here and in the chart below:

Conclusion
I’ll wrap it up here but in the next post, I’ll delve more into the resource allocation module and also explain how fault tolerance works at various levels of the Mesos stack. Meanwhile, I encourage readers to provide feedback, especially regarding if I am hitting the mark with these posts and if you see any errors that need to be corrected. I also respond on twitter at @kenhuiny.
You can find my next post on persistent storage and fault tolerance in Mesos here and my post on resource allocation in Mesos here. I can encourage you to read my post on what I think is going right with the Mesos project. If you are interested in spinning up and trying out Mesos, I link to some resources in another blog post.

Ken,
Nicely done! this provides a lot of clarification and insight into the maturity of Mesos
Reblogged this on Capacitive Flux and commented:
Mesos and other resource scheduling technologies will be an essential part of the next generation data center platforms.
[…] part 1 of this series on Apache Mesos, I provided a high level overview of the technology and in part 2, I went into a bit more of a deep dive on the Mesos architecture. I ended the last post stating I […]
Learned a lots and gained more confident about mesos, through translating this series into Chinese.
[…] dig deeper into the technology here, delve into persistent storage and fault tolerance in Mesos here and go under the hood of resource […]
[…] An overview of Mesos can be found here, followed by an explanation of its two-level architecture here, and then a post here on data storage and on fault […]
[…] Part 2: Digging Deeper Into Mesos […]
[…] Part 2: Digging Deeper Into Mesos […]
Reblogged this on My Blog.
Hi,ken
I am a stranger in mesos.
Today I read your post and learn a lot.Thank you very much.
As you said in this post that slaves regularly reports on its available resources so that the master can constantly make new resource offers.
But I have a question,that is, how slave regularly reports on its available resources to master.I have read code of mesos,but not found real-time communication between slave and master in resrouces.Can you give me some help about this and tell me where is the code that slave report on the resources to master.Thank you.
ps:I am sorry for my poor English.And I will send message to you in twitter in case of my email not receiving your reply.Because I am in China.
[…] Digging deeper into Apache Mesos […]